
Intelligent Document Processing (IDP) is a combination of technologies that convert a variety of documents and files into actionable data for your business needs. Modern IDP can incorporate computer vision, artificial intelligence (AI), natural language processing (NLP), advanced pattern matching, and machine learning (ML) to extract, analyze, sort, classify, and store huge volumes of data with little to no human intervention.
And it’s come a long way in recent years.
You may have experienced the drudgery of scanning stacks of invoices, receipts, contracts, HR documents, etc., in the quest to “go paperless” in the past. You might have dealt with optical character recognition (OCR) tools that produced less-than-ideal results, forcing you to go back and look at those original hardcopies to figure out the contents of the scanned documents. But modern advancements mean that data projects that were impossible to accomplish just a few years ago are now handled with speed and unbelievable accuracy.
As a result, IDP can improve back-office efficiency, reduce errors, and boost productivity with very little human intervention.
Let’s take a closer look at how IDP works—from when the document is first digitized, to how the computer understands its contents, to how it’s routed for next steps.
Watch this previously recorded webinar to continue learning:
What Types of Data Does IDP Handle?
IDP takes data that is unstructured or semi-structured and converts it into structured, or machine-usable, data. What does that mean?
Structured data organizes contents in a way computers can easily recognize. This data type is found in databases and spreadsheets, where column headers or other labels, such as XML tags, allow the data to match a type. This is the easiest type of data to process because it contains metadata.
The most basic definition of metadata is “data about the data.” And metadata is a key to classifying and sorting information. In HTML, XML, and other coding languages, developers can precisely define contents by surrounding them with metadata tags. For instance, an XML document might contain the following pieces of information:
<vendor> Cat Things, Inc. <vendor />
<item> Purple Catnip Octopus <item />
<price> $7.99 <price />
An AI robot can immediately recognize these three data items.
Semi-structured data comes from documents containing the same data but not in the same format or layout. For example, the invoices from your vendors contain most of the same information as above: the vendor name, the product or service received, and the cost. However, these pieces of information aren’t labeled with the convenient metadata tags that structured data has. Even if the invoice contains labels, one vendor’s invoice won’t look the same as another’s. Although a human wouldn’t have trouble figuring out what’s what on a simple invoice, this poses a slightly greater challenge for AI.
Unstructured data refers to data that is freeform. Much of the important day-to-day communications with our internal and external customers are unstructured: emails, text messages, transcribed phone messages, content typed into text entry fields on a web form, and social media posts. Most word processing files are also unstructured because they don’t have precise metadata describing their contents. That makes this the most difficult type of data for AI to handle.
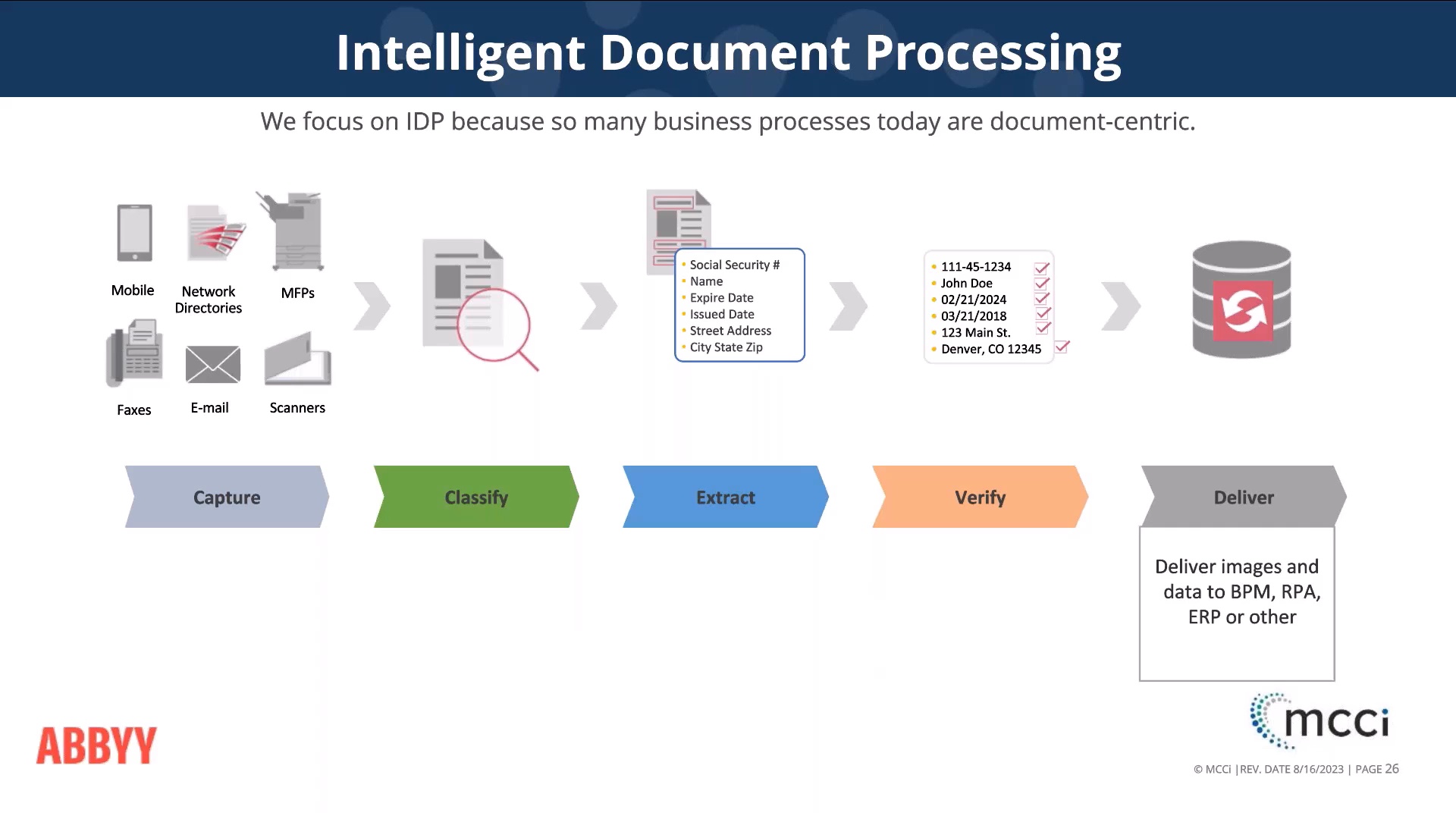
Intelligent Document Processing Steps
So, keeping all this in mind, let’s look at how IDP resolves problems and manages all data types.
1. Document Capture
If you’re starting out with a physical document, it first needs to be converted into an image and uploaded into the computer. This is traditionally done through a scanner, but in the modern day you could also simply snap a picture with your smartphone. While documents usually start out as paper, document capture can include scanning from microfiche and microfilm, too.
2. Image Processing
Once the document has been scanned, you need to check that the image is clear enough for the computer to read. Modern photo editing software often makes this a one-click process to sharpen or de-speckle the image.
3. Automated Integration
Now that you have a clear image, the computer takes over. Computer vision algorithms analyze and process these new digital files to discover the data:
- Optical character recognition (OCR) recognizes typed text and converts it to digital text.
- Intelligent character recognition (ICR) handles the challenging task of deciphering handwriting into text.
- Optical mark recognition (OMR) looks for check marks, filled circles and boxes, and other content indicators on surveys, tests, and scan sheets.
4. Document Classification
Next, machine learning algorithms analyze each portion of the document and assign metadata to it. The algorithm has two primary methods of extracting data:
- Text Classification: An algorithm finds keywords and text patterns. It can look for specific named entities (people, organizations, locations, codes, monetary units, and many others). It can even learn to assess emotional content (for instance, if a document is a complaint or a positive review) through natural language processing (NLP)
- Visual Classification: an algorithm looks for a logo, QR or barcode, specific image, or even the overarching document layout to visually classify the document. For instance, the algorithm can be trained to recognize a document as an invoice from a particular vendor based on a logo.
Once the document has been classified, the computer creates metadata tags describing its contents. For instance, if the document is identified as an invoice, it would create data fields for all of the elements you’d expect to find on an invoice. The data is becoming more and more structured—and therefore easier for the computer to process.
5. Natural Language Processing
The computer now recognizes the type of document it’s dealing with. But that isn’t always enough for the computer to know what to do with the document, especially if it contains large amounts of unstructured data. That’s where Natural Language Processing (NLP) comes in. NLP is a form of AI that analyzes language to extract its meaning—“reading” the text much as a human would!
6. Data Validation
At the data validation stage, either a human or a digital worker (robot) checks that the new metadata is accurate.
For instance, a digital robot could compare the extracted data with information in a database. If the document in question is a driver’s license, the name, DL number, and DOB might be compared against a state driver’s license database. If the data doesn’t match, the system can flag a human to review the information for errors.
Or in the case of an invoice, suppose the computer couldn’t identify a date. A human may need to go into the system and input the correct data. At this point, the human can even train the algorithm to find the date on a similar document in the future.
7. Integration
Finally, during Integration, the labeled data and its metadata are linked to the human-readable documents, usually the original PDFs, word processing files, images, and scanned documents.
The document can then be routed for the appropriate next steps using business process management tools. This is done based on pre-defined rules for the document type and metadata details. A job application could be routed to the appropriate HR manager, an invoice could be routed to the right department based on the vendor, or a record could simply be filed in the appropriate location in a Laserfiche repository.
Benefits of Intelligent Document Processing
IDP allows agencies to visualize the flow of work through process stages, observe any bottlenecks and delays, and adjust as needed. As a result, your employees spend less time doing repetitive work that can generate errors, and your organization gains efficiencies and improves quality control. In addition, a system like ABBYY FlexiCapture can create alerts to ensure compliance with rules and help you identify more opportunities for improvement.
IDP in Action: Automated Accounts Payable
In the City of Coppell, TX, three engineering staff members used to spend three days per week processing invoices. To free up staff members for more valuable work and eliminate data entry errors, leadership of this 42,000-resident North Texas city consulted with our experts. Together, we implemented an intelligent document processing solution powered by ABBYY FlexiCapture. ABBYY FlexiCapture communicates seamlessly with Tyler Technologies Enterprise ERP, resulting in much faster processing of payments—from days to hours!

